Why is Using get_dummies a Bad Idea for your ML Project?
Dealing with categorical data in machine learning models the right way!

Most of the Machine Learning algorithms do not understand categorical data (e.g. cat breed as in the above data set).
How can we make ML algorithms understand such categorical values?
We could completely get rid of categorical data and train only on the numerical data.. your model is likely to be not so discriminative as with the categorical values (fed into the ML algorithm in a way it understands).
A better approach would be to convert such categorical values into numbers. But how?
This is in fact quite prevalent in ML. This process of converting categorical values into numerical values is called encoding.
While there are many ways to encode, label encoding and one-hot encoding are the two most popular approaches.
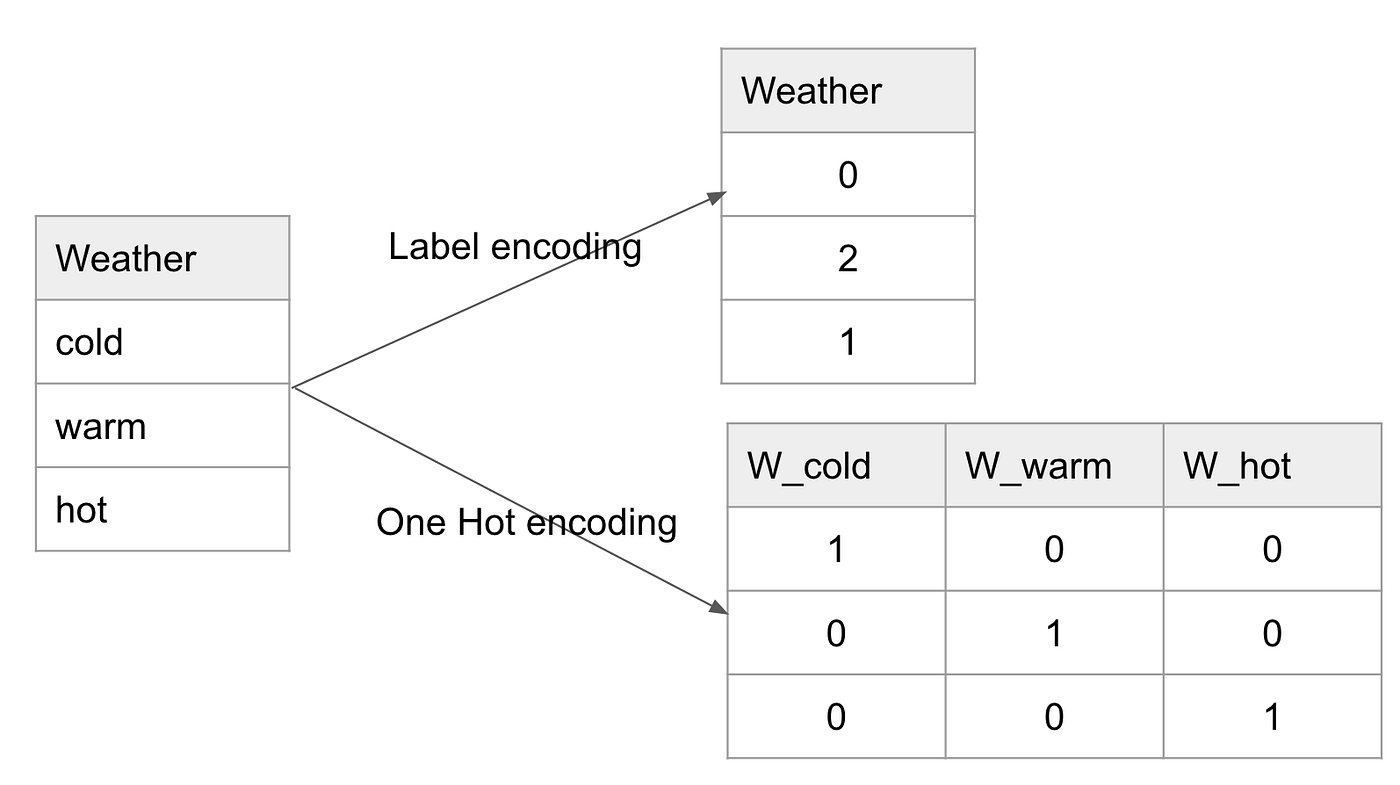
Which encoding should I use for my categorical column?
It depends! (This is usually the best answer for any question)
It depends on the type of categorical field you are dealing with and also the machine learning algorithm model you are using (e.g. don’t use one hot encoding if you are using tree based algorithms). If the categorical field is naturally ordered, we go with label encoding.
Did you notice one caveat with the above label encoder?
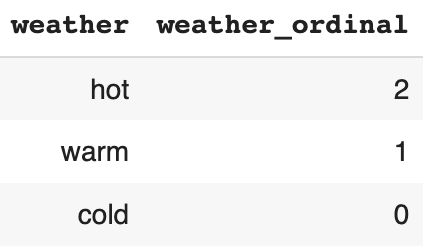
Good catch! We would expect cold -> 0, warm -> 1, and hot -> 2 to preserve the order and have some measure of the temperature. However, sklearn LabelEncoder assigns numbers in a different order.
import pandas as pd
from sklearn.preprocessing import LabelEncoderdf_w = pd.DataFrame({"weather": ['hot', 'warm', 'cold']})
LabelEncoder().fit_transform(df_w['weather'])
Output:
array([1, 2, 0])Why? Any guess?
LabelEncoder orders the categorical values in alphabetical order and then assigns an integer value starting from zero.
There is no easy way to tell the order to your program. You’ve got to either order them yourself or create an explicit map like below and then use the good old map function in Pandas.
weather_map = {"cold": 0, "warm": 1, "hot": 2}
df_w['weather_ordinal'] = df_w['weather'].map(weather_map)Output:
Why does this order matter?
ML models tend to create “virtual mappings” with data points with similar values in close proximity and dissimilar values in different regions. Preprocessing our data to tell the ML model these are in fact ordered helps the ML model do a better job.
Now back to the main topic today. When would we use One Hot encoding? And how?
We use it when the order does not matter or when the data should not be ordered to give wrong signals to the ML model!
Take cat breeds for example: British Shorthair, Bengali, and Shirazi. Can we order them in any way that makes sense? Not really.
In this case, we want to tell the ML model that the distance between these breeds is equal. One way to do this is to use one hot encoding. It does not impose any order on the encoded values.
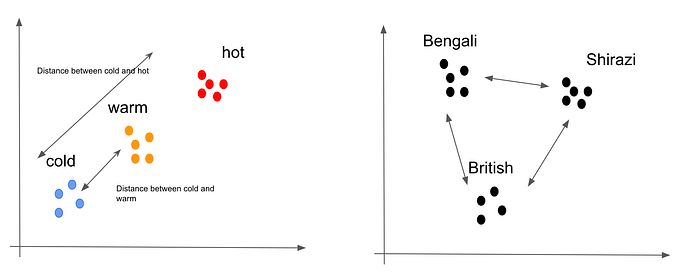

If you compute the Euclidian distance between these data points, you will readily find that it is always the square root of 2. That’s the point of one hot encoding!
One popular way to perform one hot encoding is to use pandas get_dummies method.
The following code snippet shows it:
df_c = pd.DataFrame({"breed": ["Shirazi", "British", "Bengali"]})
#get the one hot encoding and then concat with the original DF
pd.concat([df_c, pd.get_dummies(df_c[["breed"]])], axis = 1)This is cool. You may ask “I don’t see why we can’t use the same get_dummies with the dataset I am going to train a ML model!”.

There are a couple of problems in doing so.
If we could apply the get_dummies to the whole dataset — it would have worked to some extent. BUT, it is WRONG to do so! Bias creeps into your testing data. Let me explain.
When building an ML model, I cannot emphasize enough the importance of separating out testing set from the training set at the beginning before you do any encoding or scaling.
Let’s say we separate our cat dataset into training and testing sets as shown below and then perform the one hot encoding of breed column.
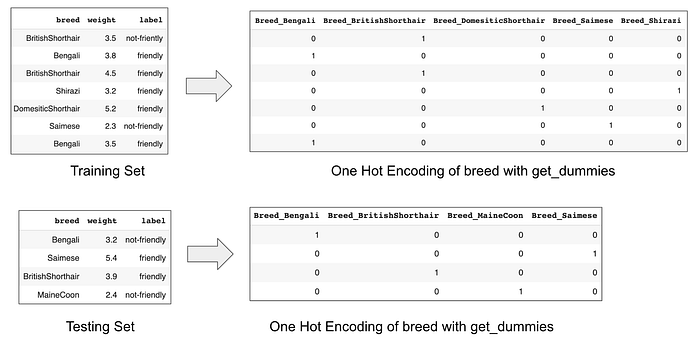
Do you spot any issues here?
The first thing that is apparent is the dimensions of the encodings are different. While the training set introduces 5 columns, the testing set has only 4 columns. Our trained ML model gets confused if we try to predict the testing set with a different dimension.
Second thing is that the testing set has a new column named Breed_MaineCoon. ML models cannot predict on test datasets with new fields.
What can we do about it?
We must “decide” the “new” fields with the training dataset and use the same set of fields with the testing set.
In order words, we “fix” an encoding model with the training set and we stick with it. We use this fixed encoding model to encode the testing data.
sklearn OneHotEncoder comes to our rescue here.
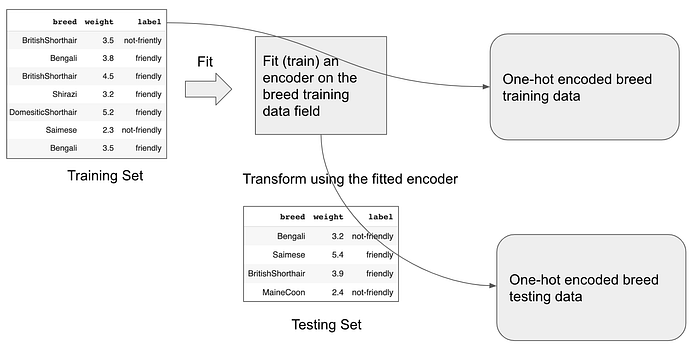
Here’s how you fit and transform the breed column in the training set:
import pandas as pd
from sklearn.preprocessing import OneHotEncoder#fit
ohe = OneHotEncoder(handle_unknown = 'ignore', sparse = False)
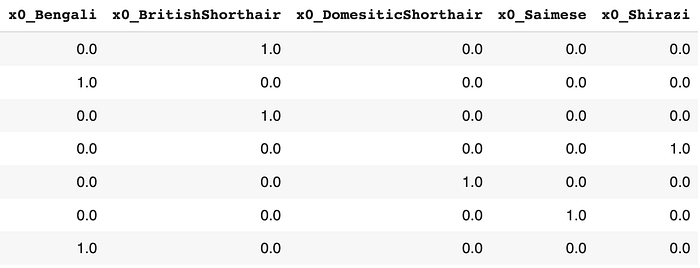
ohe.fit(df_train[['breed']])#transform
df_breed_train = pd.DataFrame(ohe.transform(df_train[['breed']]), columns = list(ohe.get_feature_names()))
Output:
Now we use the fitted model (ohe) to transform the breed column in the testing dataset. Note that we DO NOT use testing data to fit the model. This is a very common mistake even some experts make.
df_breed_test = pd.DataFrame(ohe.transform(df_test[['breed']]), columns = list(ohe.get_feature_names()))Output:

There is no magic in machine learning. ML models can only predict well on test data that is very similar in shape to training data. (If the testing data is very different from the training data, the model won’t do a good job at predicting).
Thus, we focus only on the categories we have seen in the training data. We tell the fitted encoder to “ignore” new categorical values found in the testing set. Notice the last row in the testing set is all zero as our encoder does not recognize the category MaineCoon.
In practice, we usually perform predictions on unseen data, and therefore it is a good idea to save your encoder into a file so that you can load the same encoder to transform when you want to make a prediction on a new data point later.
Bonus:
We follow the same principle when we scale/normalize the data in our training and testing sets. We first fit a scaler/normalizer on the training data and then use the fitted scaler/normalizer to scale/normalize the test data.
Take Aways:
- Never ever encode or scale your whole dataset when you are training machine learning models.
- Fit a model on the training data and then use the model to transform the testing set.
- Use sklearn OneHotEncoder to do so.
Practical Advice:
Experience 1: While it is logical to use ordinal encoding for categorical values with some order (temperature levels, grades, etc.), and one hot encoding for categorical values with no order (e.g. cat breed, favorite fruit, etc.), I treat the encoding method as a hyperparameter, meaning I try both encodings on categorical data and use the one that performs better on the metric I am focusing on (e.g. precision or recall).
Experience 2: Also, one hot encoding may not be the correct solution for certain machine learning algorithms. For example, it is recommended not to use one hot encoding when using decision tree based models like a random forest.
Experience 3: You have to be careful not to overfit. Check if your encoding creates a significant gap between the train and test performance. You may want to try a different encoding or reduce the categories in the one hot encoding by bucketing.
Experience 4: There are ML algorithms handling encoding for you (e.g. LightGBM, CatBoost). You may want to try them as well.
Feel free to reach out to me if you have any questions. I’d love to hear your feedback. That helps me write more articles like this.
PS: Have you checked what would happen if you press the like button more than once :)
Stay hungry!